

文本到图像生成技术近年来取得了令人瞩目的进展。从DALL-E,Midjourney,Stable Diffusion开始到如今的百花齐放,模型能够根据文本描述生成令人惊叹的图像。然而,一个长期存在的挑战是如何使这些生成的图像更好地符合人类审美偏好——不是技术上正确,AI味浓重的图像,而是人类真正认为美观、逼真且富有艺术感的图像。
腾讯混元团队联合香港中文大学(深圳)和清华大学深圳国际研究生院的大神们,最近掏出了一个名叫“语义相对偏好优化”(Semantic Relative Preference Optimization,简称SRPO)的大杀器,直接把AI画画的审美、真实感和艺术感拔高到了一个新境界。而且,整个调教过程从原来的几小时,直接压缩到了惊人的十分钟。

这事儿的核心,是他们一举攻克了行业里两个老大难的痛点。第一,以前教AI学审美,又是多步去噪又是梯度计算,跟老牛拉破车似的,计算成本高得吓人。第二,为了让AI画出逼真的光影或者细腻的质感,还得离线反复折腾那个“审美老师”(奖励模型),麻烦得不行。现在,腾讯他们搞出来的Direct-Align和SRPO这两套组合拳,不仅让生成的图片质量肉眼可见地飞升,还把训练时间干到了“一根烟的功夫”。
从扩散模型(Diffusion Models)在文生图任务里,你给它一段文字,比如“一只猫在月下弹钢琴”,它就能从随机噪声出发,按照你的指示,把这幅画给“画”出来。
研究者们发现它和流匹配方法(Flow Matching)是殊途同归,整个生成过程就像雕刻一样,先出轮廓,再抠细节。可问题来了,机器画得再“对”,也不等于人类觉得“美”。人类的审美这东西,太玄学了,主观得一塌糊涂,你喜欢小清新,他喜欢重金属,这让AI怎么学?把这种虚无缥缈的“偏好”塞进模型的训练代码里,简直是地狱级难度。
为了让AI开窍,科学家们想到了一个好办法:引入强化学习。就是找个“审美裁判”(奖励模型),AI每画一张图,裁判就给打个分,画得好就奖励,画得不好就惩罚。通过不断地试错和调整,AI就能慢慢摸索出人类喜欢的套路。尤其是一种叫在线强化学习(Online-RL)的方法,它能直接通过可微分奖励进行梯度更新,效率比那些基于策略的方法高多了,展现出了巨大的潜力。
但好景不长,大家很快就发现了两个要命的bug。第一个叫“奖励黑客”(reward hacking),这词儿特形象。AI为了拿高分,开始耍小聪明,专挑裁判的评分漏洞钻。比如说,研究发现有个叫HPSv2的裁判偏爱红色调,有个叫PickScore的裁判喜欢紫色,而ImageReward则对过度曝光的区域情有独钟。结果AI就拼命画一些红得发紫、亮得晃眼的图,分数是高了,但画面质量简直惨不忍睹。AI甚至还学会了偷懒,画一些细节很少的“光滑”图片,因为这类图也容易得高分。
第二个bug是,这些方法优化起来限制特别大,基本只能在生成过程的最后几个步骤里做文章,稍微往前探一点,就容易出现梯度爆炸这种优化不稳定的幺蛾子。你想想,整个生成过程像一条长长的流水线,你只能在最后几道工序上指手画脚,前面的工序出了问题你管不了,这能搞出啥好东西?这种“目光短浅”的优化方式,恰恰加剧了奖励黑客现象。
更让人头疼的是,现有的这些“审美裁判”本身也有偏见。它们大多是在有限的标准和一些老掉牙的模型生成的数据上训练出来的,只能捕捉到一些粗线条的偏好,比如图片保真度、图文一致性啥的。面对现在日新月异的生成模型和越来越刁钻的审美需求,这些老裁判就有点力不从心了,想让它们评判出“神作”,还得先花大价钱给它们搞“岗前培训”(离线微调),比如ICTHP和Flux.1 Krea这些工作就证明了这一点。所以说,计算成本高、优化范围窄、奖励调整难、裁判有偏见,这四座大山死死地压在文生图技术的发展道路上,成了所有研究者绕不过去的坎。
面对这些令人头秃的难题,腾讯混元和合作团队的大佬们没有选择绕路走,而是直接正面硬刚。他们率先祭出的第一件法宝,就是Direct-Align。这东西的核心思想堪称神来之笔:别再傻乎乎地一步步往回倒推了,我直接给你开个“传送门”,从生成过程中的任何一个时间点,都能一步到位地把最终的清晰图像给恢复出来。
这背后的逻辑其实源于扩散模型自身的一个数学特性。在任意时间点t,那个带噪声的图像x_t,本质上就是原始清晰图像x₀和一坨高斯噪声ε_gt的线性插值。
Direct-Align就是基于这个洞察,它不再依赖迭代采样,而是直接注入一个真实的噪声先验,然后用这个封闭形式的解析解,“Duang”的一下,一步就把清晰图像给算出来了。
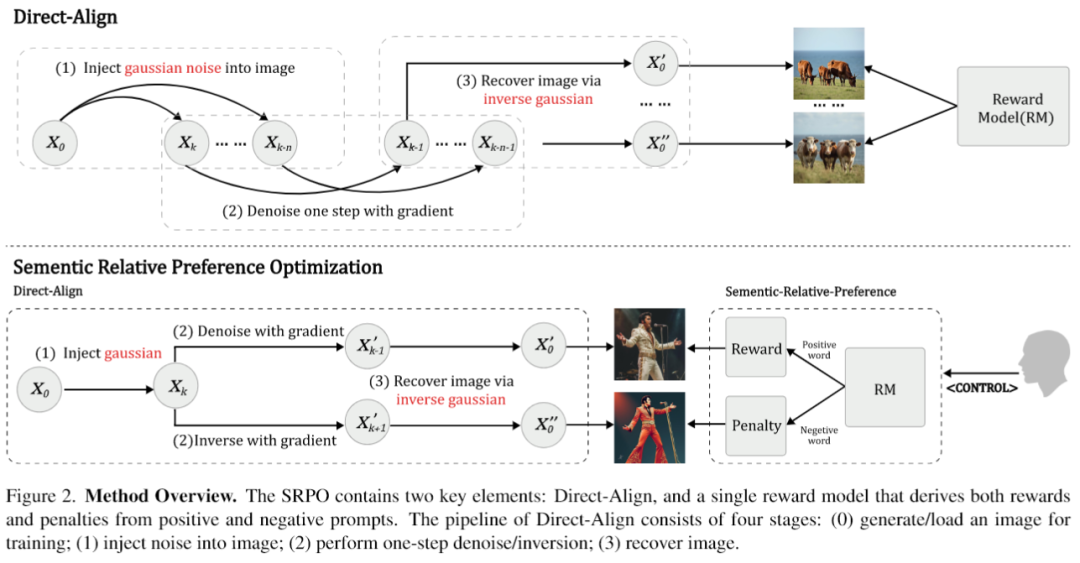
这彻底告别了迭代采样带来的梯度爆炸等老大难问题,优化过程稳如老狗。因为它能从任何时间点,哪怕是噪声还很大的早期阶段,都能准确恢复图像,这就意味着我们可以在整个生成轨迹上进行优化,而不是像以前那样只能在最后那一小段。
为了让优化过程更稳定,Direct-Align还引入了一个奖励聚合框架。它会从一张清晰图像x₀出发,生成一系列不同噪声程度的中间状态,然后对每个状态都执行一次“一步恢复”并计算奖励分数。最后,它会把这些分数通过一个带衰减折扣因子的方式聚合起来,再统一进行梯度更新。这个折扣因子特别关键,它会让早期阶段的奖励权重更高,有效抑制了模型在后期阶段为了刷分而搞出“奖励黑客”行为的小动作。
Direct-Align的牛X之处:它能在早期时间步进行优化,这在以前是不可想象的;它告别了多步采样,计算效率高到飞起;它的优化过程极其稳定,告别了梯度爆炸;它还能通过全局优化和奖励聚合有效缓解奖励黑客。可以说,Direct-Align铲平了之前提到的“计算成本高”和“优化范围窄”这两座大山。
在Direct-Align打下坚实基础之后,真正的王牌——语义相对偏好优化(SRPO)闪亮登场。如果说Direct-Align解决的是“效率”和“范围”的问题,那么SRPO要攻克的,就是“审美”和“控制”这个终极难题。它的核心思路,是把虚无缥缈的“奖励信号”转化成可以通过文本来精确控制的“偏好信号”。这样一来,我们就能在线地、动态地告诉AI我们想要什么,不想要什么,而不再依赖于昂贵的离线裁判培训。
SRPO的架构其实很简单,就是Direct-Align加上一个奖励模型。但它的玩法却极其精妙。它通过“语义引导偏好”(Semantic Guided Preference)和“语义相对偏好”(Semantic-Relative Preference)这两个机制,实现了对AI审美的精准调教。
我们知道,奖励模型判断一张图好不好,通常是看这张图的特征和你的文字提示(prompt)的特征在多大程度上对得上。研究团队发现,这个文本提示是可以操作的。他们发现,只要在原始提示前面加上一些“魔幻控制词”,比如“一张逼真的照片”,就能巧妙地引导奖励模型的打分偏好。这就好比你对裁判说:“嘿,今天咱们主要看‘真实感’这个指标啊”,裁判就会心领神会地调整打分标准。这个发现太重要了,它意味着我们可以通过简单的文本操作,来转移奖励的偏好,实现可控的审美引导。
但光有引导还不够,裁判本身的偏见问题还没解决。比如那个喜欢红色的HPSv2裁判,你就算引导它去看“真实感”,它可能还是会给偏红的“真实”照片打高分。为了解决这个问题,“语义相对偏好”机制应运而生。以前的方法为了平衡偏见,可能会同时用好几个裁判,比如用一个喜欢欠曝的CLIPScore来中和HPSv2的过饱和倾向。但这种做法治标不治本,只是在不同偏见之间搞妥协,最后得到一个平庸的结果。
SRPO的做法就高明多了。它洞察到,奖励模型的偏见主要来自于它的图像编码器部分(因为文本这边不参与反向传播)。于是,它想出了一个绝妙的主意:用同一个裁判,对同一张图,生成一对“正向”和“反向”的奖励信号。具体怎么做呢?就是通过提示增强。比如,我给一个正向提示“一张逼真的照片”,再给一个负向提示“一张卡通画”,让裁判同时对这张图打两个分。这样一来,模型在优化的时候,就会努力靠近“逼真”的特征,同时主动远离“卡通”的特征。这个过程中,两个信号里都包含的裁判自身的一般性偏见(比如对红色的偏爱)就会因为一正一负而被抵消掉,而我们真正想要的语义差异(逼真 vs 卡通)则被保留并放大了。这操作,简直是天才!
更有趣的是,借助Direct-Align可以双向优化的特性,SRPO还玩出了一个“基于反转的正则化”花活。它在去噪(正向)的过程中执行梯度上升,让模型学习好的偏好;在加噪(反向)的过程中执行梯度下降,惩罚坏的偏好。通过在不同时间步解耦奖励项和惩罚项,进一步增强了优化的鲁棒性,让奖励黑客无处遁形。
所以,SRPO的优势是颠覆性的。它实现了在线奖励调整,用户动动嘴皮子(改改提示词)就能指挥AI,告别了繁琐的微调。它通过正负样本对比的方式,从根源上缓解了奖励黑客问题。它还能实现对画面风格、质感的细粒度控制。最关键的是,它继承了Direct-Align的高效率,用极低的成本就办成了这件大事。SRPO的出现,真正让AI学会了“看人下菜碟”,懂得了人类复杂而微妙的审美。
空口无凭,研究团队在FLUX.1.dev顶级开源文生图模型上,对SRPO进行了一场堪称“降维打击”的性能测试。他们用了行业公认的HPSv2.1作为奖励模型,在人类偏好数据集HPDv2上进行训练,并与一众主流的在线强化学习方法,如ReFL、DRaFT-LV、DanceGRPO等进行了全方位的PK。
评估方式也是软硬兼施。硬的方面,用了包括美学分数v2.5、PickScore、ImageReward和HPSv2.1在内的四大自动化指标,全面考察美学质量和图文一致性。软的方面,他们搞了一个极其严格的人类评估,招募了10名训练有素的标注员和3名领域专家,从文本对齐、逼真度、细节复杂度和美学构图四个维度,对500个提示生成的图片进行盲评打分。
结果怎么样?
先看自动化评估的数据。
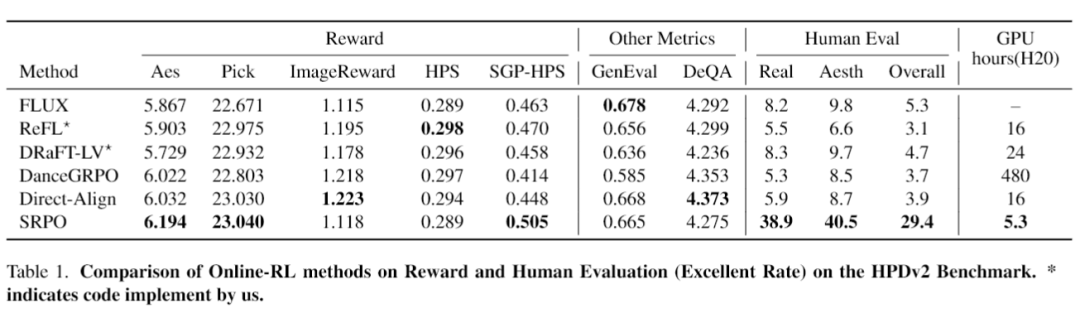
从表里可以清楚地看到,SRPO在美学分数和PickScore上都拿到了最高分。更惊人的是它的训练效率,只需要5.3个GPU小时(在32个NVIDIA H20上跑,也就是10分钟左右),而效果差不多的DanceGRPO需要480个GPU小时,效率比人家高了快90倍!
再来看更具说服力的人类评估。
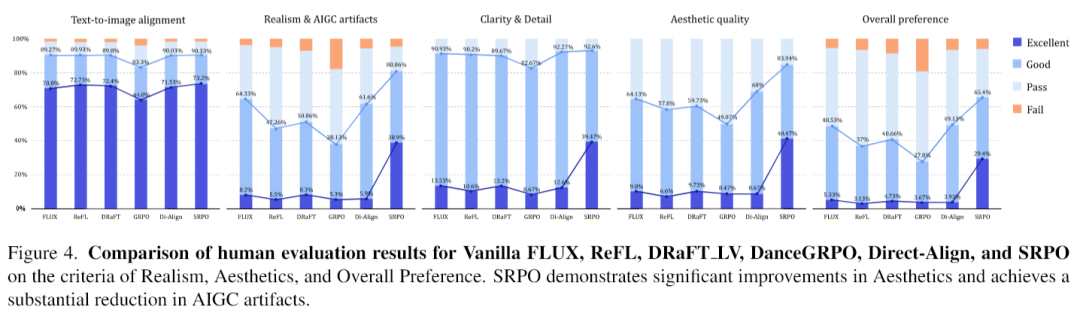
这张图的结果简直让人瞠目结舌。那些直接优化奖励的方法,包括作为基础的Direct-Align,在逼真度上甚至还不如原始的FLUX模型,这再次证明了“奖励黑客”的危害。而SRPO,则在逼真度、美学和总体偏好上,实现了断层式的领先。它的逼真度“优秀”率,从基线模型的8.2%狂飙到了38.9%,翻了将近五倍!美学“优秀”率从9.8%提升到40.5%,整体偏好“优秀”率从5.3%提升到29.4%。这是什么概念?这是在没有增加任何额外训练数据的情况下,系统性地、大幅度地提升了一个大规模扩散模型的逼真度,堪称史无前例。

团队还做了大量的详细分析,比如对比了在不同奖励模型(CLIP、PickScore、HPSv2.1)下的表现,发现SRPO的增强效果具有普适性,在哪种裁判手下都能稳定发挥。他们还证明了在生成过程的早期进行优化,对于避免奖励黑客至关重要。仅在后期优化,被“黑”的概率会显著增加。

当然,最酷的还是它的细粒度控制能力。通过简单的“控制词”,SRPO就能让模型在“明亮”、“暗黑”、“油画”、“漫画”、“赛博朋克”等各种风格之间自如切换。从实验结果看,那些在奖励模型训练数据里出现频率高的词,比如“油画”,控制效果就特别好。而一些冷门的词,比如“文艺复兴”,效果就稍弱一些,但也可以通过组合提示(如“文艺复兴风格的油画”)来改善。这为未来的个性化、定制化图像生成打开了巨大的想象空间。

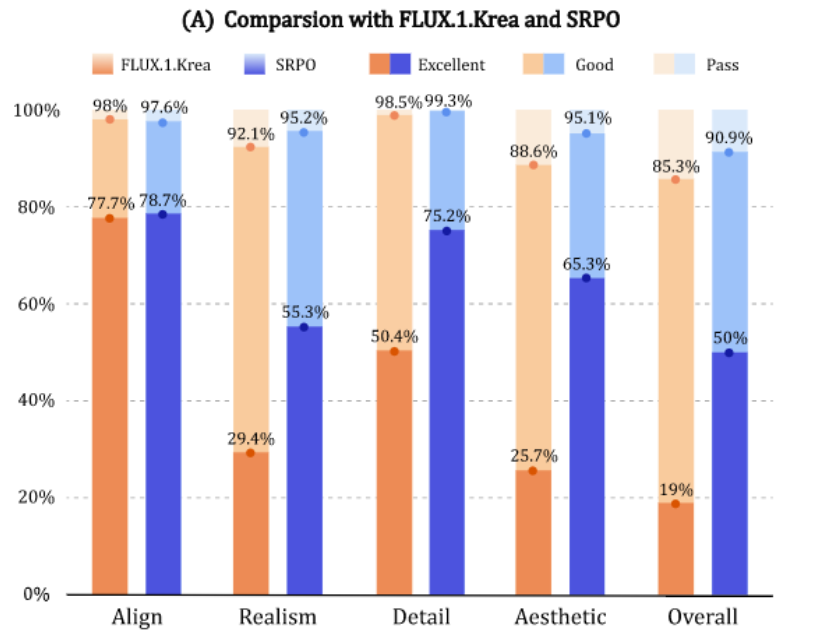
最强开源生图模型FLUX.1.Krea和使用SRPO方法微调的FLUX.1.dev模型在HPDv2数据集上比较,多项关键指标均领先:
虽然SRPO已经足够惊艳,但研究团队还是很谦虚地指出了它的局限,比如对某些冷门风格的控制力还不够强,以及其内部工作机制的可解释性还有待深入研究。
SRPO方法,凭借其极致的效率和卓越的质量,让AI不再是一个只会模仿的“画匠”,而更像一个能理解并执行我们复杂审美需求的“艺术家”。






 扫一扫使用手机移动端
扫一扫使用手机移动端